-
Our Teams
- What We Do

Citadel Securities Corporate Solutions
Valuation Metrics, a Citadel Securities Corporate Solutions offering, provides clients with focused and effective targeting of institutional investors—with deep insight into the factors that impact their investment decisions.
Understand
why investors buy and sell your shares
Prioritize
investor meetings with greatest potential
Gain insight
into investors’ likely response to corporate action (e.g. IPO, M&A)
Uncover institutional investors’ interests
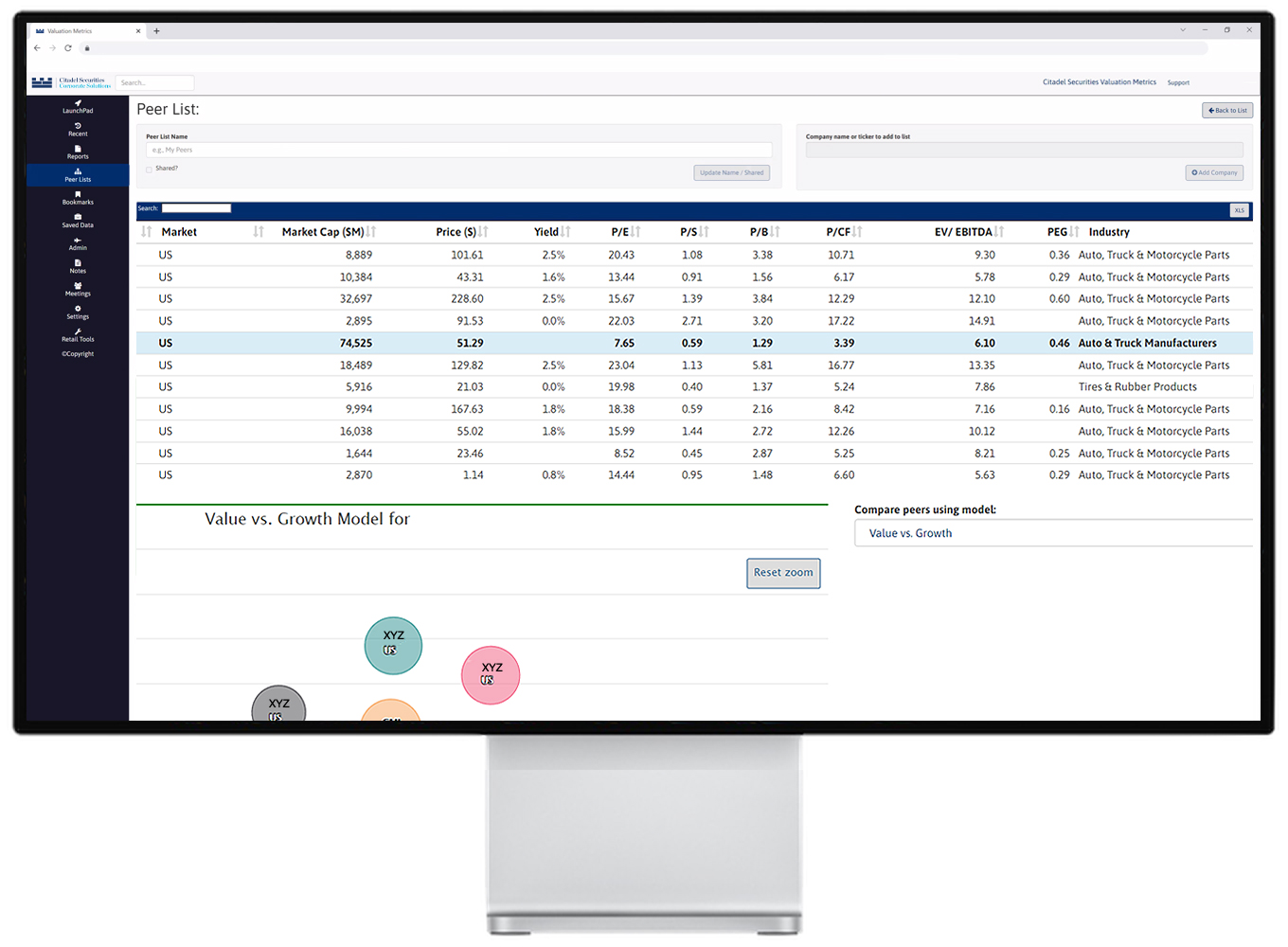
Using predictive modeling and proprietary quantitative analytics, we help our clients identify institutions likely to buy or retain their shares based on fit with their investing strategy, both prior to and after becoming publicly listed.
As a result, our clients are empowered to engage in the highest impact interactions.
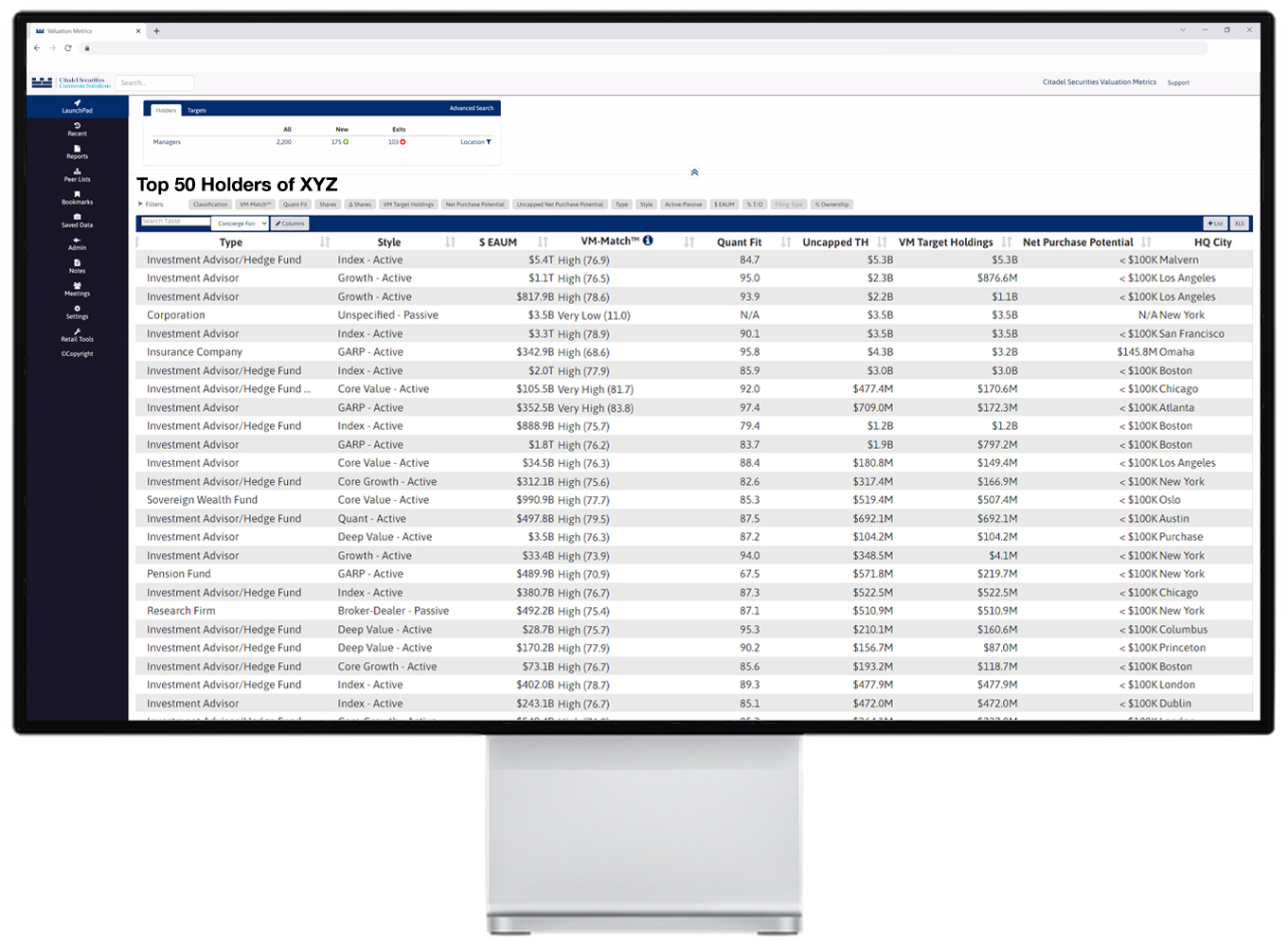
Our algorithm creates and analyzes statistical themes for virtually every company and institution in the world. We combine over a hundred fundamental inputs, dozens of valuation models and trend analyses into a powerful predictive engine.
We aggregate real-time data from investor datasets to identify potential investors based on our clients’ unique criteria.
Learn More
- What We Do